GoogLeNet¶
1. 들어가기¶
GoogLeNet은 2014년에 ILSVRC14에서 우승한 모델입니다. 같은 대회에서 발표되어 주목받은 다른 모델로는 2위를 차지한 VGGNet이 있는데, 둘 다 Lin의 Network in Network(NIN)의 영향을 받고 있다는 점이 주목할 만 합니다.
NIN에서 GoogLeNet은 크게 세 가지의 개념을 차용했는데, 바로
- MultiLayer Perceptron(MLP)
- Global Average Pooling(GAP)
- 1x1 Convolution Layer
입니다. NIN 자체는 좋은 성능을 가진 네트워크를 제시하지는 못했으나, 그곳에서 제시된 위의 개념은 고무적이고 참신하여 추후 여러 모델에서 그 컨셉이 차용되었습니다. GoogLeNet도 그 중 하나입니다.
2. GoogLeNet의 배경¶
2014년의 당시에, 딥러닝 모델은 일종의 한계에 도달해 있었습니다. 일반적으로, 네트워크의 성능을 향상시키는 직관적인 방법은 네트워크의 크기를 늘리는 것입니다. 이 크기는 보통 넓이와 깊이를 의미하며, 넓이란 곧 노드의 갯수를 뜻합니다. 즉 패러미터의 갯수를 가리킵니다. 깊이는 레이어의 계층 수를 말합니다.
다시 말해 네트워크의 성능을 올리고 싶다면, 노드 수를 늘리고 레이어를 많이 쌓으면 됩니다. 그렇다면 무작정 네트워크의 크기를 늘리면 성능이 좋아질까요? 그렇지 않습니다.
큰 네트워크란 두 가지 구조적 문제점을 안게 됩니다.
첫 번째는 큰 네트워크는 많은 패러미터를 지니게 된다는 점입니다. 패러미터의 갯수가 많아지면, 오버피팅이 일어날 가능성을 떠안게 됩니다. 이를 해결하려면 학습에 사용할 데이터의 갯수를 많이 늘려야만 하는데, 이는 현실적으로 불가능하죠. 두 번째 문제는 네트워크가 커질수록 컴퓨터의 리소스를 기하급수적으로 많이 사용할 수밖에 없다는 점입니다. 게다가 이렇게 차지한 용량이 꼭 효율적으로 사용된다고 볼 수는 없겠죠. 레이어의 weight가 학습에 따라 0에 가까워진다면, vanishing gradient 문제에 봉착하게 될 것입니다. 용량을 과하게 사용하면서도 그만큼의 성능을 내지 못하게 됩니다.
당시에는 이런 문제를 해결하기 위해 Dropout을 이용하였습니다. 패러미터 수를 늘리면서도, 오버피팅의 문제를 해결하기 위한 노력이었습니다. 그러나 이를 통해서도 문제가 완전히 해결된 것은 아니었고, GoogLeNet의 개발자는 좀 더 근본적인 해결이 필요하다는 결론에 다다르게 됩니다.
네트워크의 구조 자체를 손보지 않으면 안 된다는 결론에 말이지요.
3. Inception Module¶

앞서 GoogLeNet은 NIN에서 MLP의 개념을 차용했다고 말씀드렸습니다. MLP란 이전의 CNN과 다르게, Convolution 연산 후에 FC Layer를 한 번 더 거치는 형식의 구조를 말합니다.
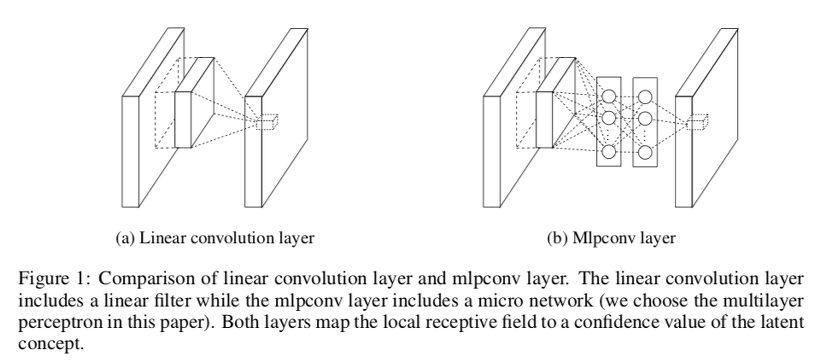
Convolution 연산 후에 풀링, 그 후에 FC Layer를 거치는 것을 하나의 모듈로 인식합니다. 이것이 하나의 전체적인 네트워크 구성과 유사하여, Micro Network라고도 부릅니다.
GoogLeNet에서는 MLP와 마찬가지로 하나의 모듈로 완성되는 구조를 만들고자 했습니다. 잘 작동하는 하나의 모듈을 완성하게 되면, 네트워크는 단순히 모듈의 적층으로 구현될 수 있기 때문이죠. 때문에 이 모듈은 단일 구조로서 네트워크 학습을 이상적으로 구현할 수 있어야만 했습니다.
Serre는 < Robust object recognition with cortex-Like mechanisms >에서 뉴로사이언스의 영감을 받아 복수 스케일의 Gabor filter를 이용하여 네트워크를 구성했습니다. Gabor filter는 사물의 윤곽선을 추출하는 필터입니다. GoogLeNet에서는 다양한 스케일의 필터를 활용하여 추상적인 정보를 인식하고자 하는 점을 이용했습니다.
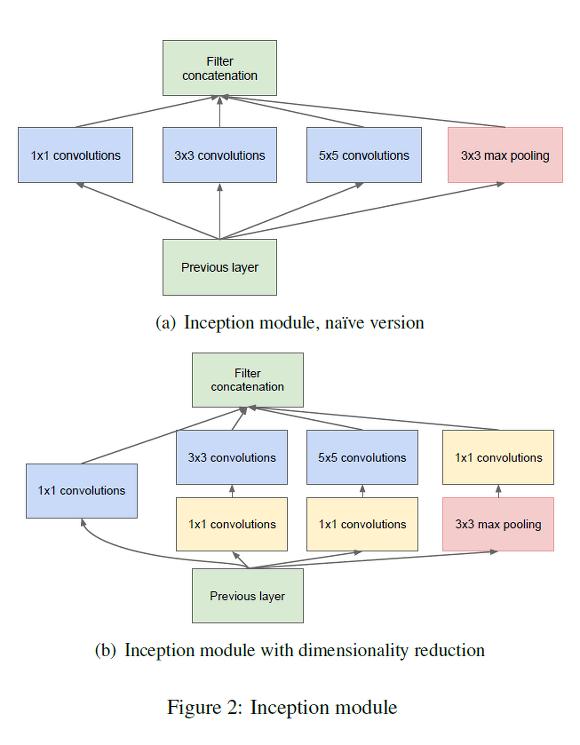
때문에 인셉션 모듈에서는 세 종류의 크기를 가진 필터가 사용되었습니다. 1x1 Convolution filter는 input image의 공간적 정보를 비교적 잘 담아낼 수 있고, 3x3과 5x5는 더 추상적이고 퍼져있는 정보를 보존합니다.
Figure 2(b)를 보시면 1x1 convolution이 각 필터에도 적용되어 있는 것을 볼 수 있을 것입니다. 이는 어째서일까요? 공간정보를 다시 한 번 보존하기 위해서일까요?
사실은, 1x1 convolution layer가 가지는 주요한 특성 때문입니다. 바로 차원감소의 효과입니다.

위의 CCCP란 앞에서 MLP의 FC Layer 연산이 일반적인 CNN에 1x1 convolution의 연산을 가하는 것과 같다는 것을 표현하고 있습니다. NIN에서는 이 계층을 삽입함으로써 Non-linearlity를 획득할 수 있음을 시사하고 있는데, 즉 1x1 layer를 삽입함으로써 비선형적 관계에 대한 예측이 더 용이하게 된다는 이점을 줍니다.
물론 이 장점도 충분히 매력적이지만, GoogLeNet에서 보려는 효과는 비선형적 관계를 표현하는 것보다 차원감소 효과에 더 무게가 실려 있습니다. 앞서 1x1의 연산은 공간적 정보를 잘 보존한다고 말씀드렸습니다. 게다가, 필터의 갯수를 input image보다 적게 설정하는 것으로 이미지의 크기를 줄이는 것이 가능합니다. 말하자면 채널에 대한 풀링 효과를 볼 수 있게 됩니다.
이제 다시 Figure 2(b)를 보시면, 3x3 과 5x5의 연산 전에 왜 1x1 연산이 필요한지를 이해하실 수 있을 것입니다. 이 연산을 끼워넣음으로써, 공간적 정보는 보존하면서도 전체 이미지의 크기를 크기를 줄이고자 하는 목적이 있었던 것입니다.
또한, 인셉션 모듈이 서로 다른 필터를 통한 연산결과들의 합을 output image로 추출하는 데에도 명확한 이유가 존재합니다. 바로 컴퓨터의 Infrastructure에 따른 결과입니다.
앞서, 당시의 CNN이 정확도를 높이기 위해 Dropout을 사용하고 있다고 말씀드렸습니다. 이는 분명히 에러를 낮추는 데 탁월한 효과를 보여주지만, 리소스의 사용 면에서 효율적이라고 보기는 어렵습니다. 컴퓨터의 연산장치는 non-uniform한 연산을 처리하는데 취약하기 때문입니다. 실제로, 컴퓨터 연산(CPU,GPU 등)은 dense한 연산을 처리하는 데 최적화되어 있습니다.
문제는 이것입니다. 리소스 사용면을 충족하고자 하면 dense한 네트워크를 구성해야 하지만, 이는 처음에 말씀드렸듯 오버피팅의 문제점을 내포합니다. Dropout과 같은 sparse한 연산과정을 도입하고자 하면, 정확도 면에서는 이득을 보게 되지만 리소스 사용이 비효율적인 면을 띠게 될 겁니다.
GoogLeNet에서 낸 결론은, 전체적인 구조 면에서는 Sparse한 구조를 갖되 실제 연산과정은 dense한 과정을 거치도록 하자는 것이었습니다. 각 필터들이 분리된 연산과정을 거친 후 합산되는 과정엔 이러한 목적을 담고 있습니다.
이 정도면 인셉션 모듈에 대한 충분한 설명을 드린 것 같습니다. 이제 전체적인 네트워크의 구성을 보도록 합시다.
4. Network Structure¶

복잡해 보이지만 잘 뜯어보면 크게 네 구조로 나눌 수 있습니다.
- Pre-layer
- Inception Layers
- Global Average Pooling
- Auxiliary Classifier
Pre-layer 계층은 초기학습을 위해 존재하는 구간입니다. 인셉션 모듈은 저층에서의 학습효율이 떨어지기 때문에, 학습의 편의성을 위해 추가되었습니다. 이 구간에서는 일반적인 CNN 연산을 거칩니다.
다음으로는 인셉션 모듈 계층입니다. GoogLeNet에서는 총 아홉 번의 인셉션 모듈을 겹쳐 총 22층의 깊은 레이어를 구성하였습니다. 이렇게 큰 네트워크를 구성하면서도, AlexNet과 비교하여 12배나 적은 패러미터가 사용되었습니다.
전체 네트워크의 상세한 구성은 다음과 같습니다.
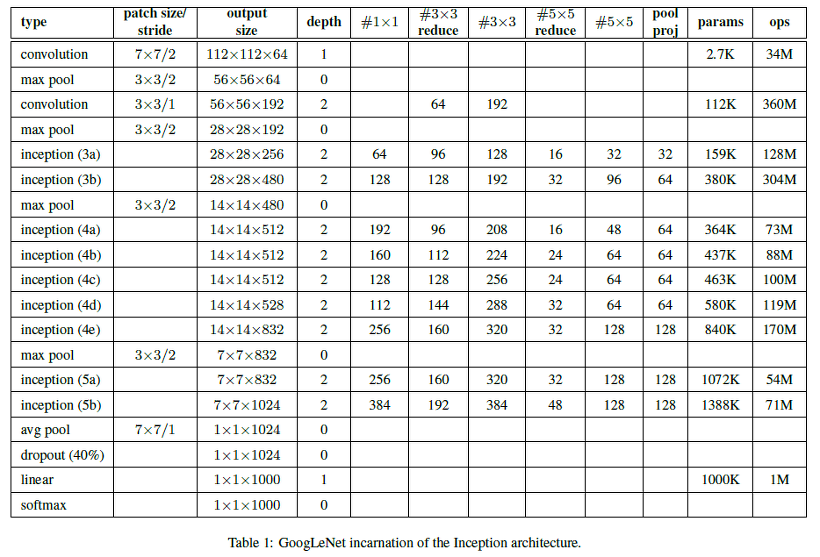
각 convolution layer에서는 activation function으로 ReLU가 적용되었습니다.
마지막으로는 GAP입니다. 처음에 소개해드렸던, NIN에서 모티브를 따 온 세 가지 중 하나입니다. 위의 표를 보시면, Average Pooling에 의해서 이미지가 1x1의 크기를 갖게 된 걸 확인할 수 있습니다. 그리고 이 이미지는 1024개의 채널을 가지고 있죠. 그렇다면 생각해봅시다. average pooling을 거친 출력은, 1x1024의 layer와 동일하다고 볼 수 있지 않을까요? 층층이 쌓인 종이탑을 옆으로 눕혔다고 생각해봅시다. 이는 분류기와 기능과도 완전히 일치합니다.
NIN에서는 실제로 FC layer를 통한 분류 과정을 GAP가 대신해줄 수 있다고 말하고 있습니다. 그런데 GAP가 분류과정을 대신해서 어떤 이점이 생길까요? 같은 결과를 낸다면 어떤 과정이 다른걸까요?
GAP의 이점은, 바로 학습 과정이 필요하지 않다는 점입니다. 이는 GAP가 어디까지나 풀링 과정에 지나지 않기 때문에 생겨납니다. 풀링은 학습과정이 아니기 때문에, 어떠한 패러미터도 추가로 발생하지 않습니다. 위의 표를 보시더라도, average pooling에 의해서 네트워크의 depth는 증가하지 않았습니다.
실제로는 GAP 이후에 FC layer가 추가되었습니다만, 이는 연산의 효과를 누리기보다는 Label에 더 쉽게 접근하기 위해 삽입되었습니다.
이제 네트워크의 마지막 부분을 설명드려야겠습니다. Auxiliary Classifier는 깊은 네트워크의 학습에 대한 우려에 의해 추가되었습니다. 인셉션 모듈이 아무리 잘 작동한다 하더라도, 깊은 네트워크는 항상 Vanishing Gradient의 위험을 안고 있습니다. 때문에 패러미터의 갱신이 잘 되지 않을 가능성이 존재하죠. 이를 피하기 위해, GoogLeNet에서는 연산 도중에 있는 image를 불러들여와 분류합니다. 인셉션 모듈 자체가 작은 네트워크의 기능을 한다고 말씀드렸으니, 층 수가 조금 적다고 해서 문제가 되지는 않겠죠. 이렇게 연산 도중에 분류를 실행하게 되면, Vanishing Gradient의 걱정을 조금은 줄일 수 있게 됩니다. 물론 학습의 정확도 문제를 대신 안게 되기 때문에, 오차 계산에서 0.3의 비중만을 갖습니다. 총 두번의 Auxiliary classification이 합쳐져 신경망 학습이 이루어집니다.
이 Auxiliary classifier는 어디까지나 학습의 용이를 위해 마련되었으므로, 학습이 완료된 후엔 네트워크에서 삭제됩니다. 학습과정에서만 존재할 수 있는 계층인 것이죠.

위의 표는 실제로 GoogLeNet이 ILSVRC14에서 얻은 성적입니다.
Optimizer로는 ASGD를 사용하여, GPU를 사용하여 총 1주일의 학습기간을 거쳤다고 합니다.
GoogLeNet은 설계단계에서 일반적인 컴퓨터로 학습하는 것을 염두에 두고 제작되었습니다. 때문에 리소스를 최대한으로 활용하며 패러미터 수를 조절하기 위한 많은 고민이 있었고, 실제로 한 epoch 내에서의 연산은 최대 15억회를 넘지 않습니다.
5. Conclusion¶
GoogLeNet은 ILSVRC14에서 1위를 거머쥐긴 했으나, 사실 VGGNet에 비해 잘 이용되지는 않았습니다. 구조가 너무 복잡하다는 것이 이유였지요. 때문에 이후로도 Inception module은 여러차례의 수정을 거치게 됩니다.
그러나 Inception module의 복잡한 구조가 어떤 이유로 조성되었는지를 생각해보게 되면, 단순히 머리가 아프기만 한 모듈이라는 생각이 들지는 않으리라 생각합니다.
Written with StackEdit.