Inception-v4, Inception-ResNet¶
1. 들어가기¶
이전에, GoogLeNet에 대해 2014년 ImageNet 대회의 우승 모델이라고 소개드렸던 적이 있습니다. 실제로 GoogLeNet, 혹은 Inception 모듈 구조는 리소스 사용을 최적화하며 높은 성능을 보여줬지만 같은 해에 등장한 VGGNet에 비해서는 저조한 활용도를 보였습니다.
이것이 GoogLeNet이 너무 복잡한 구조였던 이유가 없지는 않을 것입니다.
또, GoogLeNet이 소개된 이듬해 ResNet이 2배의 격차를 내며 우승하게 되면서 GoogLeNet의 제작자들은 새로운 궁리를 해야 할 필요성을 느끼게 됩니다.
2. 더 나은 구조¶
앞서 GoogLeNet과 같은 해에 소개된 VGGNet이 이 모듈보다 더 자주 활용되었다고 말씀드렸지만, 이는 GoogLeNet이 다양한 크기의 Convolution Layer를 사용한 것과 반대로 3x3 Convolution을 활용하여 간단한 구조를 가진다는 점이 가장 큰 차이였습니다.
하지만 VGGNet의 성능은 GoogLeNet보다 떨어졌으므로, 제작자는 여기서 하나의 아이디어만을 따오게 됩니다. 바로 필터를 인수분해하는 것입니다.
1) 인수분해¶
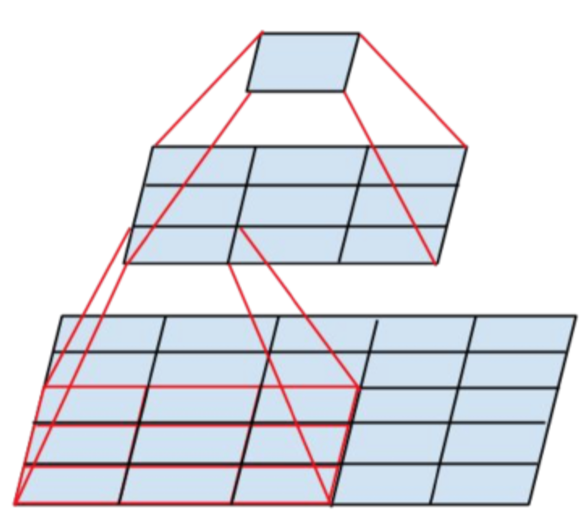
5x5 convolution을 적용하면 한번에 넓은 영역의 특징을 추출해낼 수 있지만, 25개의 패러미터를 학습해야 합니다.
그런데 이 5x5 convolution을, 3x3 convolution을 두번에 걸쳐 연산한다면 어떨까요? 3x3은 9개의 패러미터를 가지고 있으므로, 총 18개의 패러미터를 사용하여 5x5와 같은 결과를 얻으면서도 더 깊은 층을 형성하는 것이 가능합니다.
인셉션의 구조적 개선은 여기서 시작합니다. 크고 무거운 Convolution을 여러 개의 3x3으로 쪼개어, 더 깊고 가벼우면서도 구조적으로는 간단한 모델을 작성하자는 것이죠.
그런데 여기서 그치지 않고, 커널을 비대칭적으로 인수분해하는 고안도 등장합니다.
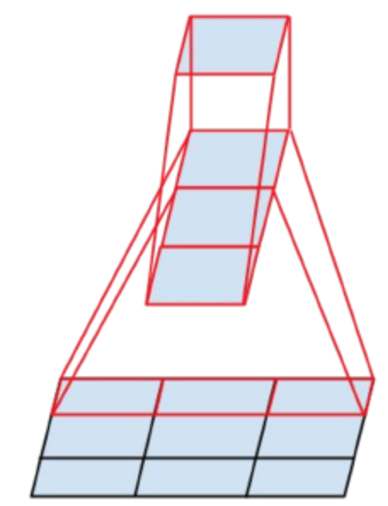
위와 같이, NxN의 커널을 1xN과 Nx1의 두 층으로 쪼개는 방법입니다. 위와 마찬가지로, 연산량이 크게 감소하는 효과를 볼 수 있습니다.
2) 그리드(Grid)를 줄이기 위한 고찰¶
앞 절로 이해해주셨겠지만, 결국 모델의 목적은 얼마나 싸고 깊은 모델을 짜올릴 수 있느냐에 있습니다. 앞에서 제시한 커널의 인수분해가 이에 해당하고, 여기서는 그리드, 즉 해상도를 감소시키는 기술에 관해 이야기하겠습니다.
연산량을 감소시키기 위해서는 이미지의 사이즈가 작은 편이 더 유리하겠죠. 이미지의 사이즈를 줄이는 데에는 두 가지 방법이 있습니다.
풀링을 하거나, Convolution의 스트라이드를 크게 하는 것입니다. 보통 이 두 방법을 모두 활용하게 되는데, 여기서 의문이 생깁니다.
무엇을 먼저 해야 할까?
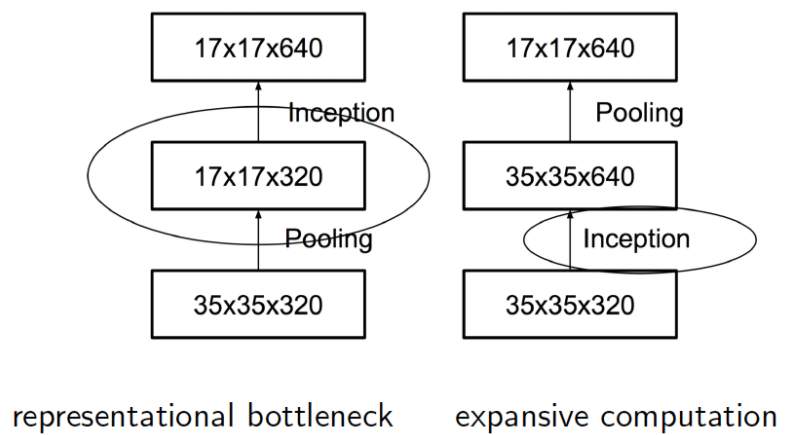
풀링을 먼저 하는 경우, 연산량이 확연히 줄어들지만 정보 보존 면에서 손해가 생깁니다. 풀링에 의해 특징 맵의 정보가 손실되는 위험이 있죠.
반대로 Convolution을 먼저 한다면, 정보 보존면에서는 뛰어나지만 연산량이 늘어나는 걸 막을 수 없습니다. 앞선 경우에 비해 4배의 연산을 시행해야만 합니다. 서로 Trade-off 관계에 있는 셈입니다.
이를 해결하기 위해 고안된 새로운 구조가 병렬 연산입니다.
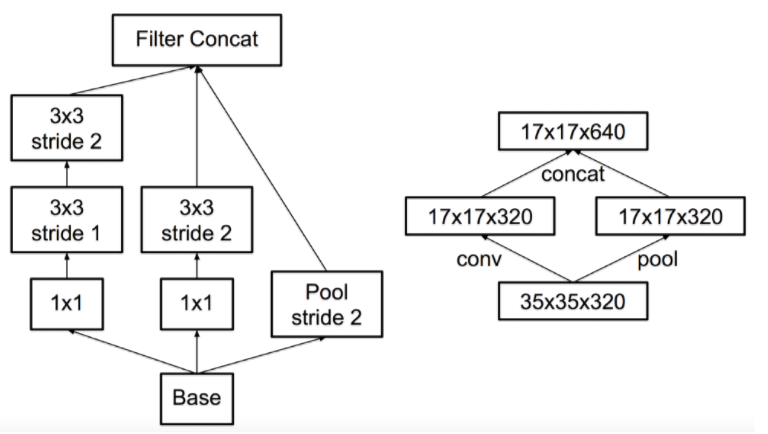
위 그림을 보시면, 스트라이드 2의 Convolution과 함께 풀링 연산이 처리되고 있습니다. 이와 같이, 두 방식을 병렬로 적용함으로써 연산량을 줄임과 동시에 특징 맵의 정보를 잃지 않을 수 있습니다.
위의 두 가지가 GoogLeNet이 개선되면서 달라진 가장 두드러진 두 특징입니다. 위의 개선점들을 조합하여 Inception v2가 등장합니다.
3. Inception v4와 Residual Connection¶
바로 v4로 넘어 온 이유는, v2에서 적용되는 개념에서 크게 바뀌는 점이 없기 때문입니다. 최적화와 정확도 증가를 위한 모듈의 변경은 있지만, 인수분해 등과 같이 큰 구조적 차이가 발생하지는 않았습니다.
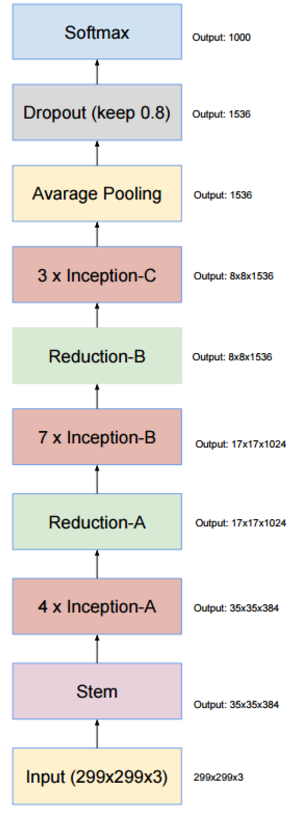
v4에서 눈여겨볼만한 구조적 특징은, 그리드 변경이 이루어지는 모듈이 구분되어 있다는 점입니다.
세 계층의 인셉션 모듈에서는 그리드의 변경이 없고, 두 계층의 리덕션 모듈에서는 그리드 사이즈가 절반으로 줄어듭니다.
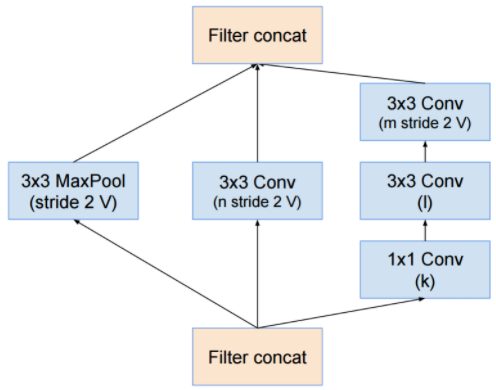 [Reduction A]
[Reduction A]
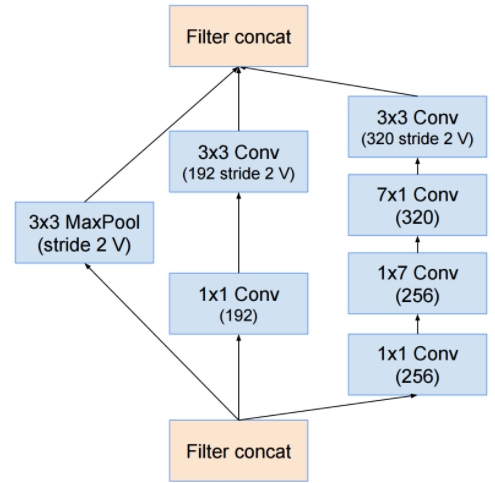 [Reduction B]
[Reduction B]
이 리덕션 모듈에서 앞서 말씀드렸던 그리드 사이즈를 줄이기 위한 고찰이 적용되며, 이는 또한 전처리 영역(stem)에서도 찾아볼 수 있습니다.
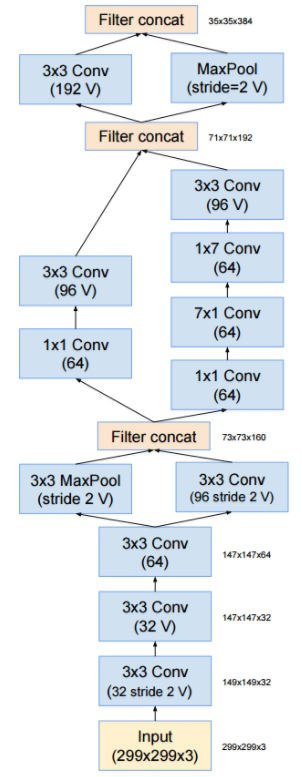 [Stem]
[Stem]
리덕션 영역과 같이, 그리드 사이즈를 줄이는 과정에서 병렬연산이 적용되었음을 알 수 있습니다.
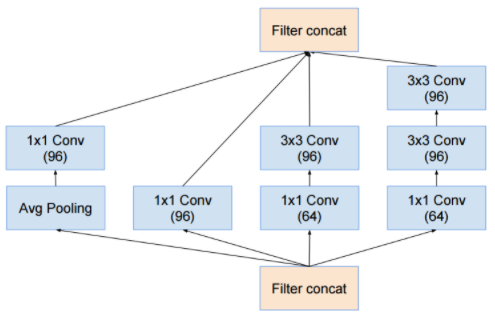 [Inception A]
[Inception A]
인셉션v1과 구조적인 면에서 크게 달라지지는 않았습니다. 다만 효율성을 위하여 커널 인수분해의 개념이 적용된 것을 확인할 수 있습니다. 이는 다른 모듈에서도 마찬가지입니다.
그럼 이제 Inception-Resnet에 관하여 이야기하도록 합시다. Inception-Resnet이란, 인셉션 네트워크에 Residual Connection을 적용한 네트워크를 말합니다. Residual Connection은 무엇일까요?
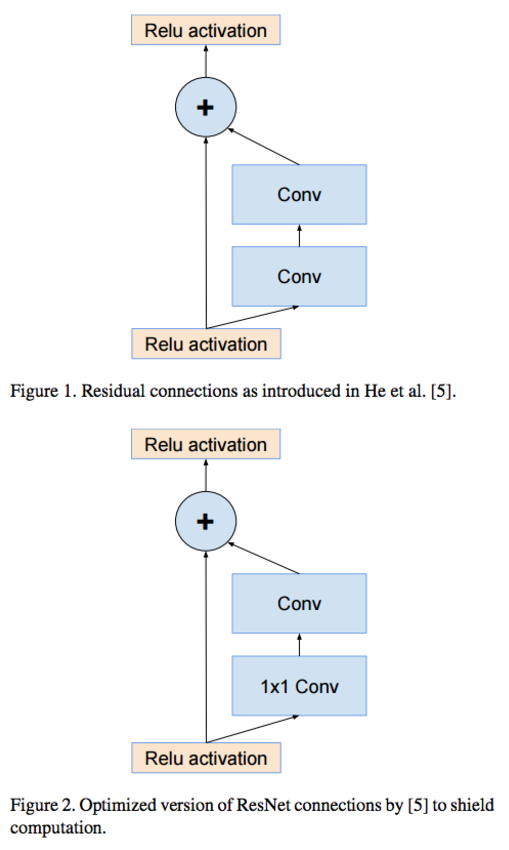
Residual Connection이란, 2015년에 등장한 Resnet에서 등장한 개념으로 아웃풋에 인풋 이미지를 합하여 리턴시키는 과정을 말합니다.
Resnet의 제작자는, 네트워크가 깊어짐에 따라 vanishing gradient가 발생하여, 학습이 제대로 이루어지지 않는 것을 방지하기 위해 Residual connection이 필수라고 설명하였습니다.
Inception-v4, Inception-ResNet and the Impact of Residual Connection에서는, 인셉션 네트워크에 Residual connection을 적용하여 그 효과를 보는 동시에, ResNet의 주장대로 과연 이러한 연결이 vanishing gradient를 위한 필수적인 요인인가 분석하고자 했습니다.
Inception-Resnet의 구조는 다음과 같습니다.
단순 인셉션 구조와 다른 점은, 인셉션 모듈에서 Residual Connection이 적용되었다는 점입니다.
위는 Inception-ResNet-v1의 모듈 구조입니다. shortcut path가 추가되어 있는 것을 보실 수 있습니다. 거기에 더해, 통상의 Inception 연산 후에 1x1 convolution이 적용된 것을 볼 수 있습니다. 이 convolution은 다른 경우처럼 차원감소의 효과가 아니라, 반대로 차원 보상 효과를 노리기 위해 삽입됩니다. 그래서 인풋에 비해 필터의 차원이 매우 큽니다.
이렇게 Residual Connection을 도입한 결과 어떤 성능적인 이점을 얻었을까요? 기존 인셉션보다 더 뛰어난 결과를 얻었을까요?
위는 단순 인셉션과 Inception-ResNet의 결과를 비교한 그래프입니다. ResNet을 추가한 쪽이 더 빠르게 수렴한다는 것을 확인할 수 있습니다. 그러나 최종적인 성능의 향상은 별로 이루어지지 않았다는 점도 보입니다. 오른쪽 테이블에서, ResNet의 추가로 인한 정확도의 개선은 거의 이루어지지 않았습니다.
4. Conclusion¶
인셉션의 개발자가 주장하는 바로는, Residual Connection은 네트워크 구성에 있어서 필수적인 건 아닙니다. Inception-v4의 존재만 봐도 그렇습니다.
그러나 모델의 수렴 속도가 상당히 빨라진다는 점은 무척이나 매력적입니다.
Written with StackEdit.